


Hey everyone! Hope you're doing well. Welcome to this blog on preparing data for training your machine learning model.
This is always has been a necessary step whether you make a statistical model, like LinearRegression or GradientBoosting, or Deep learning models like neural networks, and various others. It's important to clean and prepare your data for training to make a good model, with better results and output, because model needs to find patterns and various other things insights from the data to understand it, and give a proper prediction. If various uneven datapoints or uncleaned data lie, that makes it difficult for the model to understand and train.
So, let's get into the blog!
Why scale your data?
So many ML models use distance measures to discover the points and various similarities between them, like the algorithm KNN(K-near-neighbors). Features on larger scales can lead to underfitting of the model, hence making the model to memorize instead of learning patterns.
Feature scaling in machine learning is one of the most necessary steps during the pre-processing of your data before creating a machine learning model. Scaling can make a huge difference, between models trained on unscaled and scaled data.
The most common techniques used for feature scaling are Normalization and Standardization.
What is data normalization
Normalization is a procedure for data preparation in machine learning. The use of normalization is to change the values of numeric columns in the dataset to use a common scale, without distorting differences in the ranges of values or losing info.
Normalization avoids problems by creating new values that maintain the general distribution and ratios in the source data, while keeping values within a scale applied across all numeric columns used in the model.
How to normalize the data?
- Subtract the mean, and divide by variance.
- Make a range where data fits between 0 and 1 using division by the maximum and minimum.
- You can also use the range of -1 to +1.
- Feature the data around zero and use one as variance.
What is ROC-AUC curve?
ROC-AUC curve is a performance measurement for classification problem at various thresholds settings. ROC is a probability curve and AUC represents degree or measure of separability. It tells how much model is capable of distinguishing between classes.
Some ROC AUC Terms:
- Recall

- Specificity
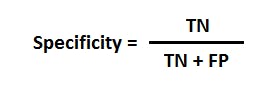
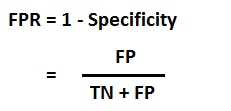
- FPR
What's hyperparameter tuning?
Hyperparameters are several model parameters that need to be tweaked and played with for the optimal learning and predictions. And, Hyperparameter tuning is the problem of choosing a set of optimal hyperparameters for a learning algorithm.
What does RMSE mean?
Root Mean Square Error (RMSE) is the standard deviation of the residuals (prediction errors). Residuals are a measure of how far from the regression line data points are. RMSE is a measure of how spread out these residuals are around.
You've now reached the end of the blog. I hope this was small and informative blog, and you also learned from it. That's it for now, See you next time!